
Security
Data security is relevant for any form or type of data, protecting data from unauthorized access, avoiding data loss, and ensuring research integrity.
View the content of this page
Switch on Security!
- Overview of the recommended storage and preservation solutions
- Overview of available software for UHasselt Personnel.
- Are you using online tools and you’re not sure if they are safe? Contact the UHasselt ICT Service Desk
- Avoid unauthorized access to your data (data breach):
- Avoid submitting personal, sensitive, or confidential data to use software applications, online tools, or platforms that are not supported by the institution (e.g., see software for UHasselt Personnel or RDM Tools)
- Uploaded work into these tools can be (re)used for other purposes. Be aware of the settings and conditions.
Five Safes Framework
To ensure that your data is safe, it is best to consider the Five safes framework, providing the maximum possible security at 5 levels:
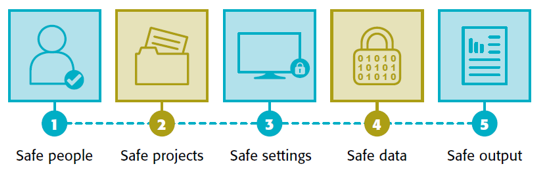
Click here to view and download a visual overview of the Five Safes Framework.
1 | Safe people
1 | Safe people
How reliable is the data processor?
Academic staff are contractually obligated to keep the data confidential and to follow standard procedures for secure data management.
Academic staff staff should have relevant training.
External collaborators or students and interns might need to sign additional agreements to properly determine responsibilities. Students and interns must equally follow institutional rules on data management.
2 | Safe projects
2 | Safe projects
How will you ensure that your project is ethical and only collects data that is necessary for the research?
We refer to the ethical and legal page for more information if you need ethical clearance for research, including human subjects, animals, or dual-use, as well as the contractual and legal issues that might apply due to the (re-)use of third-party data, intellectual property rights, or confidentiality.
When handling or processing personal data, consider the following:
- Data minimization. This means collecting only the information that is essential to answer the research question of the project.
- Storage limitations. This means that as soon as certain data are no longer needed, they should be deleted.
- GDPR register. Before starting your research project, register your research project by completing the GDPR checklist of Hasselt University. Depending on the legal basis of processing, request (additional) informed consent for collecting, processing, sharing, or publishing the data.
More information about the Securing personal data is described in the section below.
3 | Safe settings
3 | Safe settings
Do you use the security measures provided by the organisation?
Organizational and technical security measures at Hasselt University:
- Research Data Management Policy Plan
- Security consultant/ responsible (Data Protection Officer)
- Information security policy
- Continuity plan
- Notification procedure in case of physical/ technical incidents
- Raising staff GDPR awareness through information and training incidents
- Physical access control to the offices by using keys and badges
When using institutional devices (e.g., laptop) and storage solution (e.g., Google Shared Drive), the following security measures are in place:
| Identity and access management |
|
|
Data classification and encryption
|
|
|
Availability control |
|
Other security measures you can take to mitigate the risks:
- Storing data files or documents on institutional storage, and preservation solutions.
- Clean desk policy
- Use of secure systems for the transfer of data (e.g. Belnet FileSender)
- Use of secure procedures for destroying data
Levels of access control for physical and digital data:
Physical security

Digital security

4 | Safe data
4 | Safe data
Were the most effective techniques used to minimize the potential for identification in data processing and/or unauthorized access?
* Most relevant for personal and confidential data
In addition to data minimization (e.g., only handling data that is required for the project), several de-identification techniques can be applied to secure the data, such as encryption, anonymization, and pseudonymization. These techniques mask personal identifiers from data, partially or completely, reducing the risk of identifying an individual.
More information about the de-identification techniques is described in the section below.
5 | Safe output
5 | Safe output
Were the most effective techniques used to prevent the lowest possible chance of identification when sharing data and output openly with the public?
* Most relevant for personal and confidential data
Most funders require you to make your data as open as possible. Making the data open to the public creates visibility for you as a researcher and makes your data findable for reuse (more information on FAIR data vs. open data).
However, there are valuable reasons why you should be cautious or why you should not share your data openly or only after an embargo period:
- Legal issues such as intellectual property rights or valorization potential
- Personal data can be de-identified to such a level that it is possible to share your data: anonymous data can be shared with open access, and pseudonymized data can be shared with restricted access. Importantly, however, additional measures should be considered, such as informed consent from the human subjects and proper registration in the GDPR register. More information about Securing personal data is described in the section below.
Securing personal data
When you process personal data, you have the ethical and legal obligation to ensure that personal data are sufficiently protected to avoid data leaks or data disclosure.
For more information on personal data, go to the GDPR info page on intranet.uhasselt.be:
GDPR in ResearchGuidelines for securing medical and health data at UHasselt:
To ensure the security of health data, especially for projects outside of clinical trials and thus not using Castor EDC, please follow these key guidelines:
-
- Never store raw including identifiable data (a full name or national registration number) on cloud-based storage solutions (e.g., MyDrive or Google Shared Drive). Add an additional layer of encryption to the identifiable data for extra security.
- Store the key separately. The key used for pseudonymization must be kept separate from the data itself, and its access should be highly restricted.
- Always pseudonymize the data you are using for further processing.
- Restrict access to pseudonymized data.
What are personal data?
What are personal data?
Personal data are all information about an identified or identifiable natural person. Identifiable is considered to be a natural person who can be identified directly or indirectly.
Some examples of “normal” personal data include name, address, e-mail address, photo, ID number, IP address, employee number, private or professional telephone number (who’s who), login data, identification cookies, account number, CV, log data (including cafeteria, parking use, web use, surfing), camera images, personnel files, wage data, professional publications, etc.
Data concerning deceased persons or organizations are not personal data according to the GDPR and, therefore, fall outside the scope of the GDPR. Other laws and regulations may, however, apply to these data.
Special categories of personal data (sensitive personal data) are personal data that contain information regarding race, ethnic origin, political views, religious or philosophical beliefs, trade union membership, genetic data, biometric data, health data, data on a person's sexual behaviour or sexual orientation. If this information becomes publicly available, for example as a result of a data breach, this can have very adverse consequences for the data subjects.
Genetic data are personal data related to the inherited or acquired genetic traits of a natural person that provide unique information about the physiology or health of that natural person, and that come in particular from an analysis of a biological sample of that natural person.
Biometric data are personal data that result from specific technical processing with regard to the physical, physiological or behavioural characteristics of a natural person on the basis of which unambiguous identification of that natural person is possible or confirmed, such as facial images or fingerprint data.
Health data are personal data related to the physical or mental health of a natural person, including data on health services provided that supply information about their health status.
Based on GDPR in research
Special category - health data
Special category - health data
Health data are a special category of personal data related to the physical or mental health of a natural person, including data on health services provided that supply information about their health status.
Guidelines regarding the processing of medical personal data.
- Required use of an Electronic Data Capturing platform in line with Good Clinical Practices.
The platform available at UHasselt is the web-based Castor Electronic Data Capture (EDC) platform
What is an EDC?
Electronic data capture (EDC) software provides an efficient and safe platform in compliance with Good Clinical Practice (GCP) and GDPR, which can be used to build and manage your electronic case report form, online surveys, and databases. EDC software is mandatory for clinical studies but is not restricted to this type of research.
Castor EDC can easily capture clinical data and manage surveys and your electronic case report forms (eCRFs).
An account for Castor EDC can be created without a license; you can set up a project and test the functionalities. A license is needed when you want to change the type of study from Test (to try study structures, etc.) or Example (used as a reference to be shown) to Production (for real participant data).
More information regarding licensing for Castor EDC is available via The Limburg Clinical Research Centre: lcrc@uhasselt.be (co-financing for this is possible from UHasselt.
Never preserve raw data (including the direct identifiers, e.g., name and surname, national insurance number, etc.) on a Hasselt University Google Drive (proprietary MyDrive or Shared).
⇒ Solution:
- Always pseudonymize the dataset
- Store the key separately with restricted access
- Limit access to pseudonymized data by restricted access for authorized staff only
- Apply additional password encryption to these datasets
More information about the de-identification techniques is described in the section below.
Risk Assessment
Risk Assessment
When processing personal data, consider two parameters to determine which de-identification techniques are most appropriate:
- Level of sensitivity
- Probability of re-identification
The extent to which the parameters are present is determined by:
- Type of identifiers: Direct, Indirect, Strong indirect identifiers
- Uniqueness/specificity: How unique is your data?
- Prevalence of the identifier in the population
|
|
With anonymized personal data, the possibilities for identification have been 'irreversibly' removed by means of a processing technique. Anonymised personal data that can be traced back to the original individuals with reasonable effort remain personal data and are not anonymous data and therefore fall under the GDPR. For this reason, it is difficult to completely anonymise many types of research data (for example: qualitative data, large data sets with a wide range of personal data, etc.). Pseudonymised personal data (referred to as 'coded data' in previous privacy legislation) are personal data (whether sensitive or not) that can only be associated with an identified or identifiable person by means of a non-public (secret) key. Pseudonymised personal data are still personal data protected by the GDPR.
|
|---|

De-identification techniques
Best practice tip: Create a pseudonymized version of your raw dataset before you start processing and interpreting your dataset, masking personal identifiers from data, partially or completely, reducing the risk of identifying an individual.
De-identification techniques for ...
Quantitative data
Quantitative data
Quantitative personal data refers to numerical data describing a person's characteristics and is typically collected through surveys, experiments, or observational studies.
Recommended techniques and tools to de-identify quantitative data:
| Techniques |
Basic techniques:
Advanced techniques:
|
| Automated RDM tools |
Open-source software tools for anonymizing personal data:
Open-source alternatives not available via software center (yet):
|
Qualitative data
Qualitative data
Qualitative research refers to non-numeric data with data expressed in natural language (e.g., textual or visual form). For example comprehensive interviews, focus groups, personal diaries, observations, field notes, responses to open-ended questionnaires, audio and video recordings, and pictures. This methodology provides in-depth datasets containing information about peoples' perspectives, emotions, motivations, beliefs, and expectations.
Qualitative data often contain various types of personal data and a certain context in which the information is provided, making it difficult to anonymize these types of datasets fully.
Best practice tip: pseudonymizing your qualitative dataset after data collection before starting the data analysis and interpretation, especially before sharing data with collaborators or third parties.
Recommended techniques and tools to de-identify qualitative data:
| Audio & video files |
|
| Transcripts |
RDM Tools for managing transcripts:
|
| Annotation of text files |
|
| Step-by-step anonymizing qualitative data |
Guide on de-identifying data by Erasmus University Rotterdam |
Must read!
Making qualitative data available for reuse? Read the Making Qualitative Data Reusable - A Short Guidebook For Researchers
References:
- KULeuven RDM Anonymisation & pseudonymisation
- Verburg, Maaike, Braukmann, Ricarda, & Mahabier, Widia. (2023). Making Qualitative Data Reusable - A Short Guidebook For Researchers And Data Stewards Working With Qualitative Data (Version 2). Zenodo. https://doi.org/10.5281/zenodo.8160880
Neuroimaging and biometric data
Neuroimaging and biometric data
Biometric data are a special category of personal data that result from specific technical processing with regard to the physical, physiological or behavioural characteristics of a natural person on the basis of which unambiguous identification of that natural person is possible or confirmed, such as facial images or fingerprint data.
Recommended techniques and tools for neuroimaging and biometric data:
| Magnetic Resonance Imaging (MRI) data |
De-facing is the preferred de-identification technique used on MR images to mask/remove facial features such as eyes, nose, and mouth. RDM tool for automated de-facing of MRI data:
Scrubbing is a technique necessary to remove or generalize personal information or medical details in the header/metadata of image files, DICOM files, and file path names. For example, by specifying the age instead of the actual date of birth, and removing names and addresses. RDM tools for scrubbing MRI data:
|
| Electroencephalography (EEG) and physiological data |
Avoid using personal information (initials, birthdate, etc. when collecting data. However, if your files do contain personal data, remove the personal information from the header of the raw data files before sharing. RDM tool for de-identifying EDF data:
Note: EEG, heart rate, skin conductance data, reaction times to a task etc., are considered personal data when there is also information included in the dataset that links this data to an identified or identifiable natural person. |
| Virtual reality / Eye tracking data |
Raw eye-tracking data contains videos of facial features and is, therefore, a dataset that can be linked to an identified or identifiable natural person. These data should be for your eyes only and can pose an increased privacy risk. |
Encryption
Encryption is a data protection technique that transforms readable data (plaintext) into an unreadable format (ciphertext). This process uses a specific algorithm and an encryption key to scramble the data. The primary purpose is to safeguard information during both storage and transmission, ensuring that only authorized individuals with the correct decryption key can convert the data back into its original, readable form.
The use of encryption is strongly recommended by modern data protection regulations, such as the General Data Protection Regulation (GDPR). The GDPR advises using encryption for files, folders, or entire hard disks to protect personal data.
Encryption of ...
Encryption of ...
| Files |
Encrypt one or multiple files using build-in encryption (password protection) by software applications, for example:
|
| Folder |
7-Zip: download via the UHasselt Software Center or the website. |
| Drives |
Bitlocker: available on IT managed Windows devices (more information) Avoid using external devices (e.g., USB drive, external Hard Drives) to avoid data loss and security breaches. However, if you do need to use an external device, make sure to encrypt the device. Use Bitlocker To Go (available via your Windows device). |
| Sharing and transfer |
Belnet file sender allows you to share large (up to 5TB) data files securely. |